How to Get More Labeled Training Data Without Hand Labelling?
- Authors
- Published on
- 6 mins read
Manual annotation, despite its accuracy, suffers from being time-consuming, costly, and entangled with complexities. To mitigate these challenges and acquire high-quality labels efficiently for training machine learning models, several alternative techniques have emerged over the years.
In this post, we'll cover some of the popular alternatives of manual labelling and the tools that you can leverage to overcome the cost and time constraints, enabling you to move your ML model into into production more efficiently.
Weak Supervision
Weak supervision is an approach to machine learning in which high-level and often noisier sources of supervision are used to create much larger training sets much more quickly than could otherwise be achieved by manual supervision. It enables the creation of large training sets very quickly, making it great to use in any situation in which you need to adapt and iterate regularly and rapidly. Weak supervision is useful when there are frequent shifts in the distribution of your data, such as in an adversarial setting (ex. fraud detection) or just because your needs change frequently.
The key idea behind weak supervision is that labeling functions don’t need to be perfectly accurate. Instead, multiple sources of supervision can be combined using labeling functions to programmatically label data. Snorkel AI is an example of a library that uses labeling functions to combine high-level, scalable, but potentially noisy sources of signal.
Although labels obtained from weak supervision can sometimes become too noisy to be useful, it can be great starting point to look into the effectiveness of ML without investing extensive resources into manual labelling.
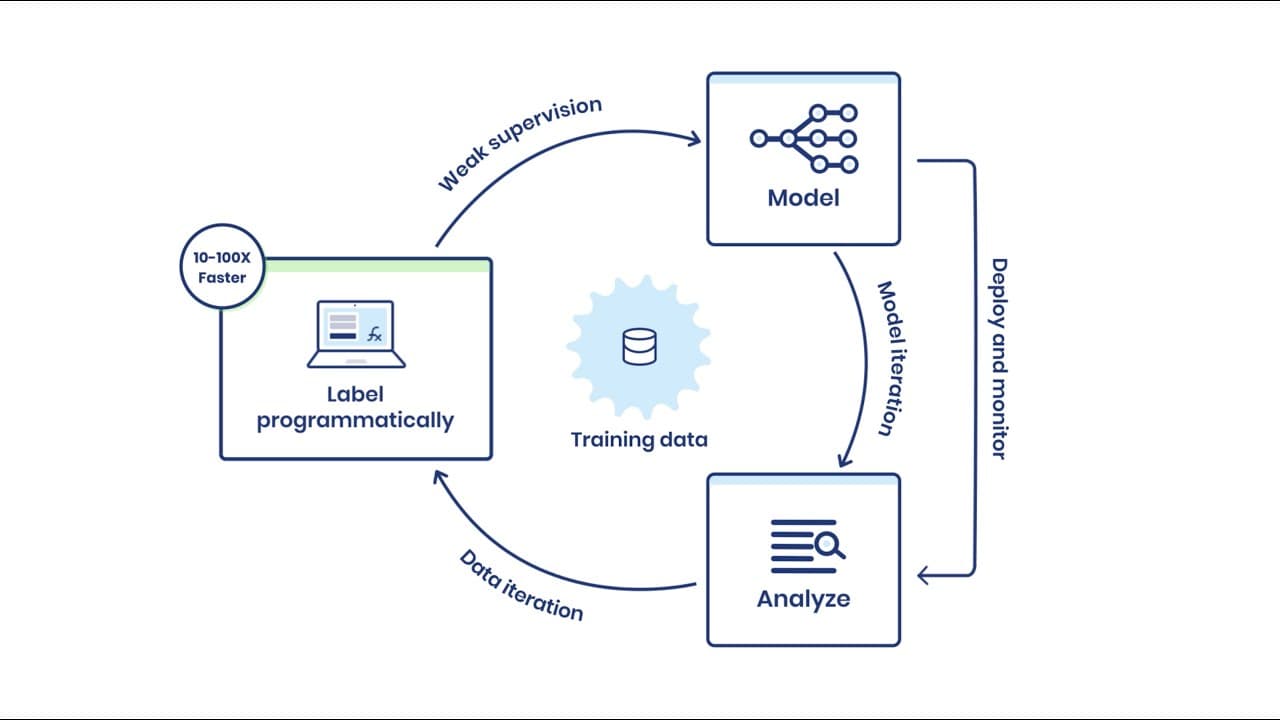
Source: Snorkel FLow
Semi-Supervision
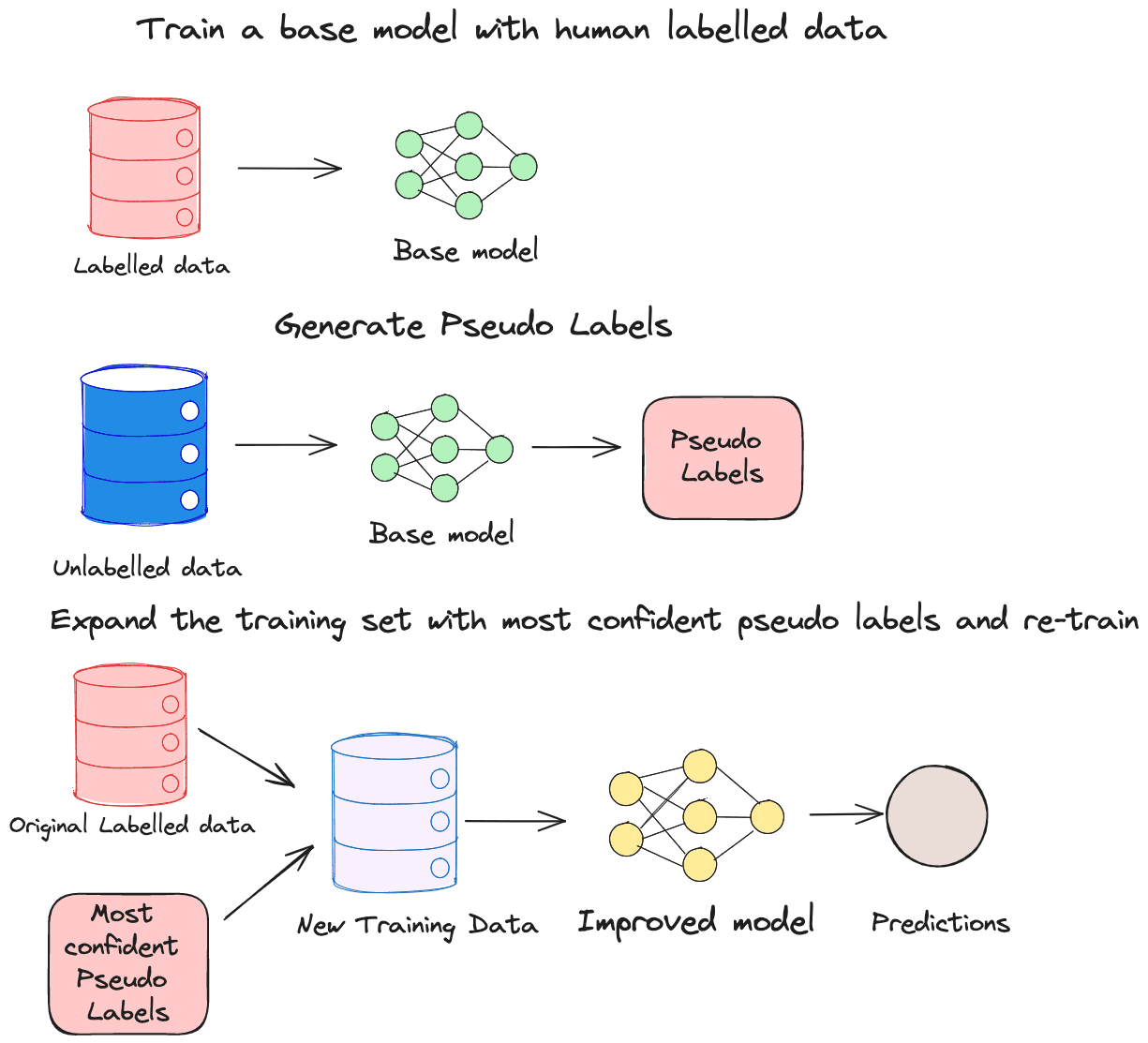
Instead of using solely on heuristics, semi-supervision generates new labels based on a small set of initial labels. It's an effective approach to generating additional labels from a limited initial set without any human involvement.
Imagine you have a small subset of data that has been carefully labeled, and a large pool of unlabelled data . With semi-supervised learning, you start by training your model using this small labeled dataset. Once the model is trained, you use it to generate probability scores for the unlabelled data. Assuming that the high probability scores are reliable and correct, you then add these inferred labels back into your training set, effectively expanding your dataset. This process is iterated repeatedly until the model performs at the desired standards.
Another method of doing semi-supervision is with the assumption that similar data has similar characteristics and output. It typically involves a cluster method or a K-Nearest Neighbour method to discover samples that share common characteristics. This leads to two approaches of labelling the data: Cluster assumptions and manifold assumptions. Cluster assumptions are based on the idea that data possesses inherent patterns that enable the clustering of data points. These clusters can then be associated with specific class labels. Whereas manifold assumptions would assume clusters that are closer to each other have similar predictions and lie on a manifold.
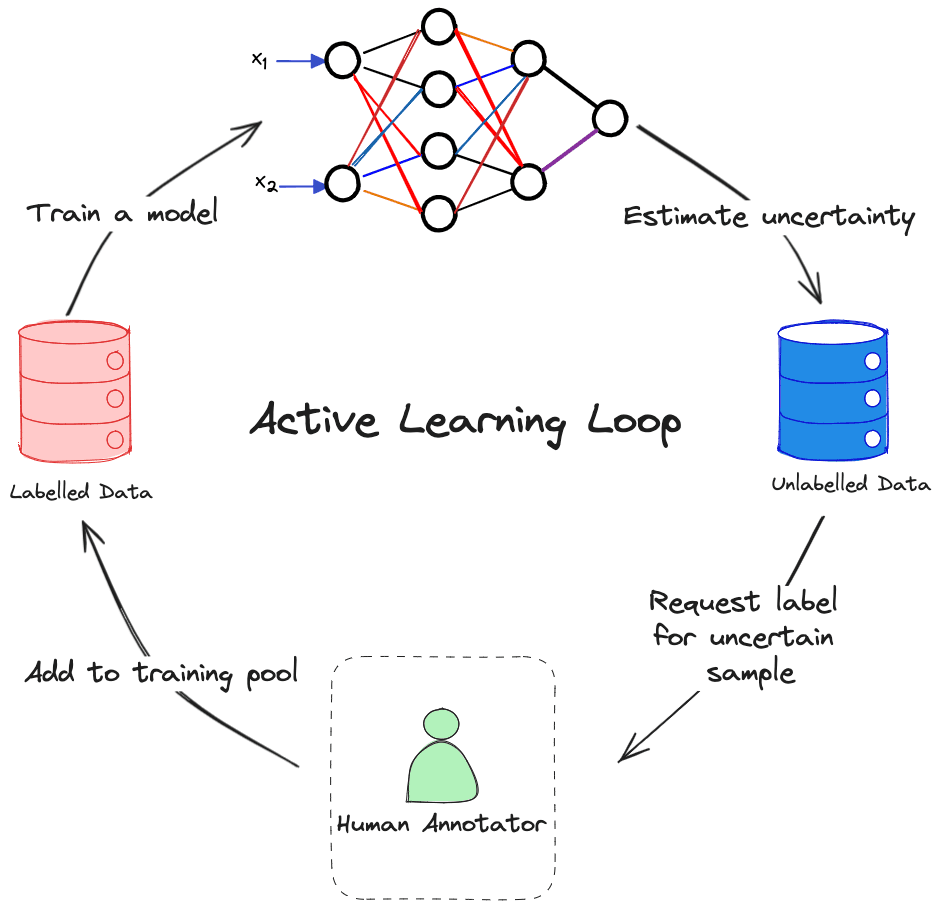
Active Learning
Active Learning, also known as "query learning," is a method where the learning algorithm takes the initiative to engage users in labeling new data points with the hope to achieve greater performance without having to hand label a large pool of unlabelled dataset. In an active learning settings, a learning algorithm (Active Learner) sends back queries in the form of unlabelled samples to be annotated by a human known as an Oracle (Usually SME). The idea behind active learning is to reduced the amount of labelled data required to train a model by selecting the most informative and representative examples for labelling.
So, how does the model figure out what's "informative"? One common heuristic is by measuring uncertainty. An Active Learner requests labels on the data points it's least certain about. Those labels would help the model understand the decision boundary better. Another approach is the "query by committee" method. Imagine having multiple candidate models with different algorithms or hyperparameters. They all get a vote on which samples to label next, and disagreements among them guide the labeling decisions.
There are two common patterns of active learning: pool-based sampling and stream-based sampling. In the pool-based approach, you compile a list of unlabelled samples from which your model can request labels. In the stream-based approach, data points are randomly selected from a sampled distribution, and the model decides on the go whether to label them or not.
Active learning is useful in situations where unlabelled data is abundant but manual labeling is expensive. By actively querying the user for labels, the learning algorithm can learn a concept with fewer examples than in normal supervised learning.
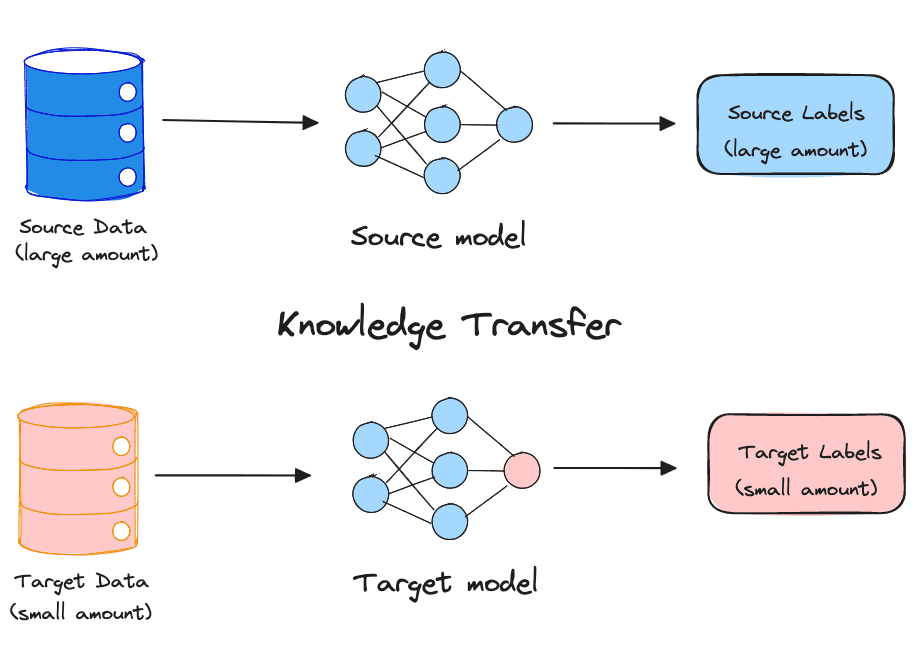
Transfer Learning
Transfer learning is another popular technique where a model trained on one task is re-purposed on a second related task. In the realm of deep learning, this method often employs pre-trained models as a starting point for tasks like computer vision and natural language processing. These pre-trained models significantly reduce the time and computational resources typically required to develop neural network models for these complex problems, elevating performance on related tasks.
Transfer Learning is particularly appealing for tasks constrained by limited labeled data. Instead of starting the learning process from scratch, transfer learning reuses a pre-trained model as the starting point for a model on a new task. It is especially beneficial when achieving satisfactory model performance using a small dataset for training proves to be difficult. Through transfer learning, significant performance gains can be achieved on a new task with only a limited amount of data, far surpassing the results possible with training from scratch.
Several sophisticated ML systems that are in production, like object detection models, utilise pre-trained models from ImageNet. Similarly, text classification models leverage pre-trained language models such as BERT, GPT-3, and other variants of large language models. This approach has significantly reduced the initial labeling costs required to construct ML applications.
Conclusion
In this post, we look at various alternatives to hand labelling that are cost-effective and allows you to quickly train and reiterate on ML model development. These methods offer diverse approaches to deal with limitations in data labelling, particularly beneficial when dealing with frequent changes in data distribution, limited labeled datasets, or situations where manual labeling is expensive and time-consuming.
Thanks for reading! Stay tuned for more insightful reads on unraveling the intricacies of the data world! If you have any questions, feel free to contact me on LinkedIn.